From Push to Pull: Completing Insurance Hub Phase 1 with CI/CD and GitOps
The previous article concluded with the system successfully running on Kubernetes, yet it still relied on a manual deployment model. While validating the cluster foundation and service manifests was a significant milestone, it also revealed a lingering operational gap: the platform had a Kubernetes runtime, but it lacked a Kubernetes-native delivery process.
Initially, the cluster offered declarative primitives and service discovery, however, the release cycle remained tethered to manual intervention. This distinction is critical because a mature runtime does not implicitly provide deployment maturity; I still faced the overhead of manual image publishing, manifest updates, and environment reconciliation.
This article addresses the final component of Phase 1, focusing on the CI/CD and GitOps work that I had postponed until now. I will utilize GitHub Actions for modular release workflows, GitHub Packages and GitHub Container Registry for artifact publication, and Flux CD for cluster reconciliation based on the repository state.
Phase 1 Scoping: Anchoring Delivery Foundation
In a previous article, I discussed the importance of thoroughly reviewing the project’s scope before committing to the Phase 1 implementation. During this review, I identified several critical gaps that required immediate attention. One significant gap was the integration of GitOps, which could no longer be postponed until Phase 6 as we had originally planned. As a result, I decided to include the CI/CD and GitOps components in Phase 1. This decision was based on practical considerations: while the initial efforts resulted in a functional Kubernetes runtime, the platform would not achieve true operational completeness without a declarative delivery path.
I found myself relying on orchestrated Make targets and manual image tagging instead of repository reconciliation. This gap was particularly evident when considering the upcoming Phase 4’s Strangler Fig migration. I anticipated that managing Java and Go versions through separate Kustomize overlays would quickly become a manual coordination challenge. Therefore, I concluded that implementing automated workflows for modular releases was not just an optimization but an essential requirement to ensure the platform remained scalable from the outset.
However, not every environment required the same delivery model. For the local development Kind cluster, I intentionally maintained a manual push model. This approach—building images locally and loading them into nodes via Make—better aligns with the iterative feedback loop I need during active coding. On the other hand, for the production-like QA environment running on K3s, I prioritized achieving full operational completeness through a proper delivery pipeline.
Architecting Delivery Path: From Requirements to Reconciliation
Transitioning from a manual “push” model to a GitOps-driven pipeline required a clear definition of what a “complete” delivery platform meant for this project. Having spent most of my career outside the context of monorepos with shared internal modules, I found it challenging to establish the objectives and select the right tools that could handle the complexities of cross-module dependencies. I needed a platform that did not just automate the path to production but also enforced the operational discipline I had established during the manual “shift” phase.
Specifically, I classified the platform requirements into five focus areas: validation, release isolation, versioning, artifact management, and reconciliation:
- Automated PR Validation: Every change, whether to a shared Java API module or a future Go service, must receive immediate feedback through linting and automated testing to catch style drift and regressions early.
- Modular Release Isolation: I needed to establish independent pipelines for APIs, shared libraries, and services to manage the monorepo’s dependency graph. This modularity ensures that a release of a shared module triggers updates only for its direct downstream consumers, preventing localized changes from causing an uncontrolled, full-stack re-release cycle.
- Scalable Versioning: The versioning strategy needed to be compatible with a monorepo and forward-compatible, ensuring that the eventual Java-to-Go migration would not disrupt our artifact history.
- Artifact Management: A centralized location was necessary for publishing both JAR files and container images.
- Declarative Reconciliation: Finally, the QA cluster state needed to be continuously reconciled with the repository.
Because the repository already lives on GitHub, I kept the delivery stack there as well: GitHub Actions for CI/CD, GitHub Packages for JARs, and GitHub Container Registry (GHCR) for Docker images. By keeping the delivery logic close to the code, I eliminated the need for external authentication and benefited from GitHub Actions’ native support for monorepo-style path filtering. Using GHCR as our OCI-compliant registry provided a unified view of our images, which was essential for tracking the coexistence of legacy Java and future Go workloads.
For the GitOps reconciliation layer—specifically for the production-like QA environment—I selected Flux CD. Initially, I considered the trade-offs between Flux and Argo CD. While Argo CD offers a rich user interface and sophisticated image automation, I ultimately chose Flux due to its “Git-centric” approach, which felt more lightweight and integrated seamlessly with Kustomize. Flux’s source controller and Kustomize controller allowed me to treat my manifests as the single source of truth, without introducing an additional UI and operational layer that I did not need for this phase. Since I was already managing my environment through structured Kustomize overlays, choosing Flux felt like a natural extension of my existing workflow rather than an additional layer of complexity to manage.
CI/CD: Orchestrating Modular Releases
Before proceeding with the implementation of our CI/CD workflows, I gave careful thought to the underlying automation strategy. The Insurance Hub is a Maven monorepo where modules share a common Git history and depend on each other through internal APIs. This structure introduced three principal challenges: establishing a versioning strategy that works for both Java and future Go services, defining safety guardrails for inter-service dependency updates, and implementing automated version bumping driven by the commit history.
Module Versioning: Decoupling Release Cycles
I evaluated two primary versioning strategies for managing our modular monorepo: a global
repository version and independent per-service versioning. Initially, the global “release
train” approach seemed appealing due to its straightforward mental model—the entire platform would
move from version 1.3.0 to 1.4.0 as a single unit. This model simplifies coordination for
tightly coupled modules and keeps pipelines clear by avoiding a complex versioning matrix. However,
it quickly became evident that this coarse-grained approach would introduce significant operational
noise. Frequent, localized changes to a small service would necessitate a version bump across the
entire stack, making it difficult to understand what had actually changed and triggering unnecessary
builds for stable components.
Ultimately, I opted for independent semantic versioning for each module. This strategic choice
aligns with the requirements of the Go module ecosystem for monorepos. In Go, a single repository
containing multiple modules must use prefixed tags—such as legacy/pricing-service-api/v1.2.3—for
the toolchain to correctly resolve sub-directories as dependencies. By adopting this pattern now for
our Java APIs, I am laying the groundwork for a seamless migration to Go in the future.
This approach also reinforces independent service lifecycles, a core principle of the microservices
architecture we are pursuing. Independent versioning ensures that consumers of the
product-service-api, for example, are not forced to adopt updates they don’t need, effectively
decoupling release cycles and reducing the risk of creating a “distributed monolith.” From a
technical safety perspective, it eliminates race conditions in GitHub Actions; since each matrix job
manages a unique, module-specific tag, multiple APIs can be built, tagged, and released in parallel
without conflicting over the same Git reference.
As a project convention rather than a strict Semantic Versioning (SemVer) requirement, I have
restricted legacy Java API versions to the 1.x.x range, reserving 2.0.0+ for future Go-based
services to maintain clarity between project eras. Additionally, I chose to keep the Maven pom.xml
versions at a static 1.0.0-SNAPSHOT for legacy modules to avoid version churn in the monorepo.
While this sacrifices some in-file version visibility, treating Git tags as the release source of
truth ensures that the system state is tied to immutable tags rather than transient working-tree
updates.
Artifact Tagging: Balancing Traceability and Immutability
The versioning approach for container images needed to be both monorepo-friendly and forward-compatible. Initially, I considered a simple SemVer-only approach to keep the image registry organized. However, while SemVer is excellent for tracking the evolution of a module, it lacks the cryptographic certainty needed to link a running binary back to a specific Git commit. If a tag is accidentally overwritten—a common risk during manual interventions—the connection between source code and cluster state would be broken.
To mitigate this risk, I implemented a dual-tagging strategy that applies both a SemVer tag and a short Git SHA to every build. The SemVer tag provides a human-friendly timeline for release management, while the SHA tag serves as an immutable anchor. After testing this approach against our modular workflows, I decided to adopt it, despite the minor trade-off of increased registry size. In my view, the benefit of having a definitive mapping between a container in GHCR and a commit in Git outweighs the overhead of managing a more aggressive image retention policy.
Guardrails: Managing Dependency Propagation
To effectively manage the complex network of inter-API and service dependencies, I implemented a strict guardrail of “single-module-per-release.” This restriction ensures that each GitHub Action run is focused on a specific domain or service update, minimizing the risks associated with partial failures or “mixed” version releases. By enforcing this atomic approach, I can guarantee that each scoped Git tag serves as an accurate point-in-time reference for the lifecycle of a specific component.
Recognizing that the policy-service-api is a critical foundation for the entire system because
multiple services depend on shared policy contracts, I adopted an active propagation strategy to
prevent dependency drift. When an API release is finalized, a specialized update-dependents job
automatically scans the repository only for consumer service modules and updates their pom.xml
versions accordingly. This change is then committed back to the main branch, triggering a sequential
release of the dependent services and ensuring the system remains aligned with the latest contracts.
Additionally, I established structural guardrails to separate internal library logic from deployable
artifacts. Infrastructure modules, such as command-bus and other API modules, are published
strictly as JAR files to GitHub Packages. In contrast, business services directly build
OCI-compliant Docker images for GHCR without going through this step. I also adopted the
Conventional Commits
standard to streamline this logic. By enforcing prefixes like chore(k8s) or feat(svc), I enable
the continuous integration process to automate versioning and provide a machine-readable audit
trail. This keeps deployment history auditable and ties each release back to an explicit repository
change.
Monorepo Workflows: From PR Validation to Release Automation
I ended up with three workflow types to manage the monorepo lifecycle. The following diagrams illustrate the logic for PR validation and the subsequent release stages:
PR Validation: Enforcing Modular Discipline
API Releases: Building and Propagating Contracts

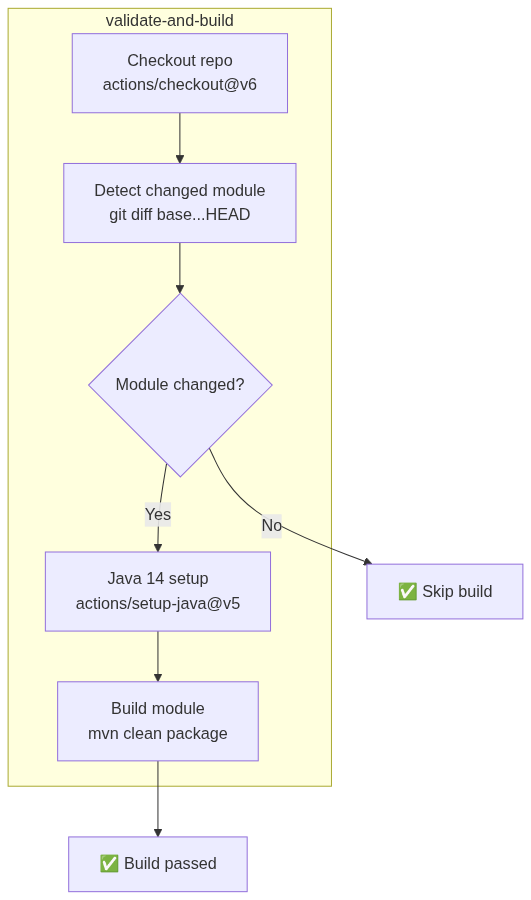
Service Releases: Automating Modular Delivery
Note: The web release workflow follows the same pattern as the service workflow (detect →
build → publish → tag). The first full pass of these workflows landed in
this commit,
which established the foundational YAML definitions and path-filtering logic.
GitOps in QA: Keeping Flux Focused on Reconciliation
While the “shift” phase successfully confirmed that our services function as Kubernetes workloads, the deployment model was still dependent on a manual “push” loop. To address this, I introduced Flux CD to manage the QA environment. This changed the delivery model from operator-driven push to declarative pull; in this approach, the cluster itself takes responsibility for fetching and applying changes, making the Git repository the definitive source of truth for the cluster’s state.
In this architecture, Flux is focused solely on cluster reconciliation. It does not decide when to release; instead, it ensures that the cluster state matches what is declared in Git. The roles are clearly defined: GitHub Actions handles the complexities of building artifacts and updating manifest versions, while Flux serves as a reliable component that pulls those changes into the environment. This separation keeps our delivery pipeline “boring” and predictable—Flux doesn’t need to manage Maven dependencies or OCI tagging strategies; it simply observes the repository and reconciles any differences.
GitOps Workflow: Flux Reconciliation Loop
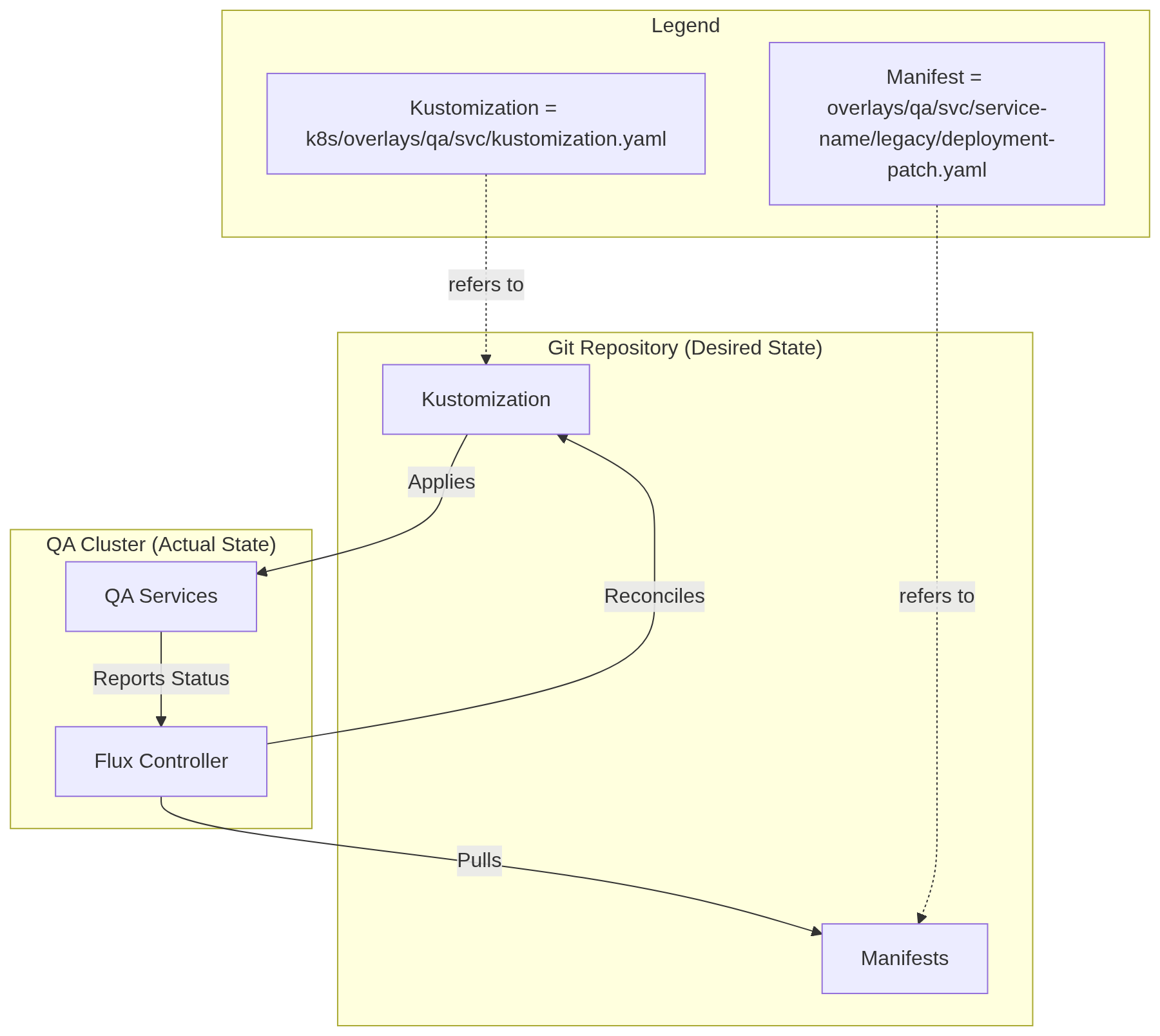
To support this GitOps workflow and maintain the reproducibility established in earlier phases, I
added several Flux-specific management targets
to the k8s/Makefile:
flux-bootstrap– Installs Flux components and connects the cluster to GitHub.flux-reconcile– Triggers an immediate pull and application of the latest Git state.flux-suspend– Pauses reconciliation to prevent Flux from overwriting manual cluster tweaks.flux-status– Provides a unified view of all Flux sources and kustomizations.flux-uninstall– Cleanly removes the GitOps controller from the cluster.
For more details, please refer to these commits: 21b266b, a943656, be4ba90.
Release Strategy: Ordering Around Module Dependencies
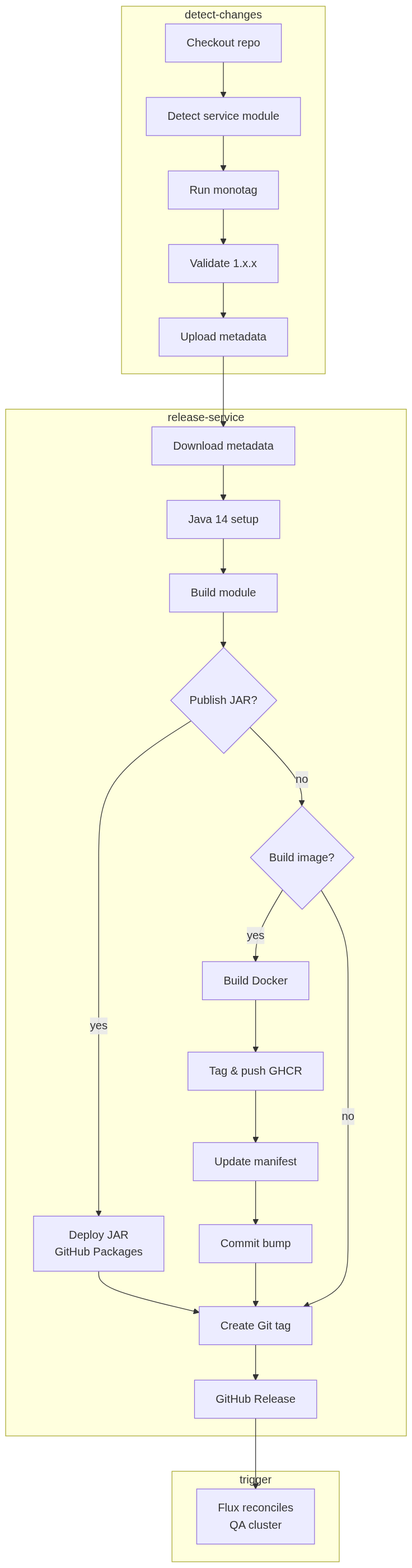
With the workflows and reconciliation model in place, the remaining problem was release order. The Insurance Hub is not just a collection of isolated binaries; it consists of a network of interdependent Maven modules. I realized early on that a “deploy all” approach would fail due to the strict ordering required by internal API consumers and implementation providers. To manage this complexity, I used the module dependency graph as a blueprint for the release sequence.
Initially, I considered a simultaneous release, but the inter-module dependencies made this impractical. The system relies on a “bottom-up” propagation model, meaning that shared contracts (API modules) must exist in the artifact registry before implementation services can successfully compile and link against them.
| Release Tier | Modules | Rationale & Procedure |
|---|---|---|
| 1. Foundation | auth-service, chat-service, command-bus-api |
Standalone identity and isolated messaging services. command-bus-api is the fundamental contract that triggers the update-dependents job. |
| 2. Core Infra | command-bus |
Released once the CI has automatically bumped the version in its pom.xml following the API update. |
| 3. Domain APIs | policy-service-api, product-service-api, pricing-service-api, etc. |
Must be released in a specific sub-order (e.g., policy-service-api before documents-service-api). Each push triggers JAR publication. |
| 4. Implementation | policy-service, pricing-service, payment-service, etc. |
These are triggered by auto-commits from the API tier. They consume the newly published JARs and produce OCI-compliant images for GHCR. |
| 5. Edge/Gateway | agent-portal-gateway, web-vue |
The final consumers. The gateway is released last as it depends on nearly all backend APIs to route traffic correctly. |
The order is mostly enforced by CI propagation, with one deliberate exception in the API layer. When
a change is pushed to a module like policy-service-api, the legacy-release-api.yaml workflow
publishes the new JAR file and identifies any downstream services that require a version bump.
However, I intentionally blocked automatic version bumping among dependent APIs—such as
documents-service-api referencing policy-service-api—to prevent uncontrolled contract cascades.
This ensures that changes to core domain objects are intentionally reviewed and acknowledged by
downstream contract owners before they are propagated further.
To trigger these releases in a controlled manner, I adopted a pattern of “chore” commits. Since I am
maintaining a static 1.0.0-SNAPSHOT in the pom.xml to avoid version churn, I needed a way to
signal to GitHub Actions that a specific module was ready for formal release.
Because the workflow is path-triggered, I used an explicit no-op change—typically adding a comment
to the pom.xml—with a commit message formatted as chore(command-bus-api): first release. This
approach effectively “pokes” the workflow for that specific path without altering the project
configuration.
For the final service rollout, the process required an additional step to integrate the workload
into the GitOps reconciliation loop. Image publication alone was not enough; the service also had to
be present in the QA overlay. For example, with the pricing-service,
the release
was triggered by two concurrent actions: adding the release-triggering comment to the service’s
pom.xml and uncommenting the service resource in the k8s/overlays/qa/svc/kustomization.yaml
file. This ensured that as soon as the OCI image was published to GHCR, Flux was already authorized
and instructed to pull the new workload into the qa-svc namespace.
This sequence transformed the first deployment from a simple command into a validation of the entire delivery architecture. By the time the gateway was successfully reconciled by Flux, I had verified not only the service code but also the automated versioning, the artifact registry permissions, and the dependency propagation logic. The first release confirmed that the monorepo could self-coordinate, turning a complex dependency exercise into a repeatable, straightforward operational routine.
Pragmatic Automation: What I Deliberately Postponed
Not every potential automation belonged in Phase 1. My primary goal was to establish a stable and clear delivery path instead of opting for an overly complex one. Given the intricacies of a monorepo undergoing foundational changes, I felt it was essential to maintain manual checkpoints to ensure that every architectural modification was intentional and verified.
Initially, I considered using Flux’s image automation to automatically update manifests whenever a new OCI image was pushed to GHCR. However, after testing the modular release flows, I decided against implementing this feature in this phase. Automated image updates can obscure the connection between code changes and cluster state changes, making troubleshooting significantly more difficult. By requiring an explicit “chore” commit to update the image tag in the Kustomize overlay, I maintain a clear, human-readable audit trail in Git. Keeping this step manual ensures that I am always aware of exactly which version is being reconciled in the QA environment.
Additionally, I chose not to implement a complex multi-loop delivery system or premature promotion orchestration. Treating each environment as a distinct entity with its own explicit configuration guarantees that the delivery pipeline is thoroughly tested in the most production-like environment—the K3s cluster. I adopted this “QA-first” strategy to avoid the added complexity of cross-environment synchronization and to prevent “configuration gravity,” where the delivery tool influences architectural decisions rather than supporting them.
Maintaining a clear and explicit system was the right trade-off for Phase 1. I applied automation only where it reduced the coordination risk of monorepo dependencies, but I refrained from using it where it might diminish visibility into cluster state changes. By anchoring every deployment to a deliberate Git commit, I ensured that the platform remains self-consistent as I prepare for the more dynamic migration in Phase 4.
Phase 1 Completion: Bridging Operational Gap
The implementation of GitOps reconciliation and modular release workflows marks the formal conclusion of Phase 1. This practical decision has established a declarative delivery path, anchoring the legacy stack to a version-controlled source of truth, rather than relying on manual commands.
The platform now features a functioning cloud-native baseline for the Insurance Hub. This includes dual Kind and K3s clusters, a comprehensive suite of containerized stateful infrastructure, and all ten legacy Java microservices operating with Kubernetes-native service discovery and S3-compatible storage.
Most importantly, the previous manual “push” model for application delivery has been replaced by a Git-driven reconciliation process. While stateful infrastructure continues to be managed through orchestrated Make targets, the entire service layer is now managed using structured Kustomize overlays and synchronized with Flux.
This transition significantly reduces operational risk for the upcoming phases of migration. Most of the coordination work is now encoded in workflows and overlays, allowing me to focus on service changes rather than the mechanics of release. I can iterate on implementations with the confidence that the state of the environment is predictable and reproducible.
With delivery automation now in place, the next priority is to enhance observability. Phase 2 will focus on improving our foundational observability by integrating OpenTelemetry with a unified Grafana Tempo backend. This sets the stage for Phase 3, where I will simplify the data layer by migrating product data from MongoDB to PostgreSQL. Together, these stages will ensure that the infrastructure and persistence strategies are unified before we begin the service-by-service Go migration in Phase 4.
Continue reading the series “Insurance Hub: The Way to Go”:
- From Java to Go: Kicking Off the Insurance Hub Transformation
- From Docker Compose to Kubernetes: Lifting the Insurance Hub into the Cloud
- Lift Completed, Now Shift: Making the Insurance Hub Kubernetes-Native (Enough)
- From Push to Pull: Completing Insurance Hub Phase 1 with CI/CD and GitOps
- Legacy to Modern: Bridging Trace Flows with Dual-Writing and Alloy